What worries the chief scientist at OpenAI? AlphaGo’s move 371 and the possible advent of Artificial General Intelligence (AGI).
A little update on the latest research developments in the area of Superalignment. What is it? Why will it matter in the future and what are some of the key takeaways for our own use of AI.
In October 2023, Ilya Sutskever expressed concerns about developing AGI that creators can no longer fully comprehend. The student at some stage may outperform the master. A reality already in the world of Chess, Go, StarCraft II, Dota 2 and other games in which AI achieved a superhuman level.
“We’ve seen an example of a very narrow superintelligence in AlphaGo,” […] “It figured out how to play Go in ways that are different from what humanity collectively had developed over thousands of years,” […] “It came up with new ideas.” 2
If you are comparing this with your own experience when using ChatGPT-4 (and possibly experiencing AI hallucinations), the latest Gemini Models in Google’s Bard (and realising it is unable to access any links when asked to go look something up) or tried to prompt Midjourney for the 10th time to provide you a picture closer to what you are trying to imagine – you are probably wondering how close we really are to anything remotely resembling AGI. But do not be fooled by the current standards – aligning AI with superhuman capabilities has a 10 year target horizon – according to OpenAI.
The Superalignment Problem has OpenAI dedicate their own research resources and additional grants to spur the ML research community into action.
“We believe superintelligence — AI vastly smarter than humans — could be developed within the next ten years. However, we still do not know how to reliably steer and control superhuman AI systems. Solving this problem is essential for ensuring that even the most advanced AI systems in the future remain safe and beneficial to humanity.” 3
Let’s have a look where some of these concerns may come from and what we can learn from the leading AI and ML researches for applying and training various forms of algorithms in a better way.
A Little Bit Of History
An easy start to track down some of the challenges is to follow the journey of Ilya Sutskever. In 2012 AlexNet won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Ilya Sutskever, along with Alex Krizhevsky and Geoffrey Hinton at the University of Toronto developed a groundbreaking convolutional neural network able to classify a dataset of 150k photographs into objects and categories. AlexNet was able to do these tasks faster and with less errors than the competition. Besides the groundbreaking research, what else did AlexNet need to win the ILSVRC? More (and better) data and more computing power.
From images, Ilya went on to work for Google and took on language next – to be more precise he started to train an algorithm to translate English to French. One of the key phrases from his 2014 research paper on Sequence to Sequence Learning with Neural Networks4: “it should do well on many other sequence learning problems, provided they have enough training data.”
In 2017, Google’s paper ‘Attention is All You Need’5 extended on this research and introduced the Transformer, advancing neural networks in natural language processing (NLP). You might have been wondering what the GPT stands for? Generative Pretrained Transformer.
From introducing the new setup for ChatGPT-1 in 2018 with 117 million parameters, to the release of GPT-3 with 175 billion parameters it can be assumed that the latest models in use today had further exponential growth of these data points.
I believe it is in the mind boggling increase of both learning parameters, impact of changes to the AI architecture and the processing power needed to achieve remarkable outcomes in such a short period of time – such as the career of Ilya Sutskever from 2012 to 2023 – that you can start to imagine what another 10 years might be capable of.
Alongside Ilya’s career and the increase of data and processing power, another field has had a big impact on AI: the revolution of Reinforcement Learning (RL) in AI. It may have been a gradual process from it’s early starts in the 1950s and beyond, but since the heavy use in AlphaGo’s approach to winning Go – it has taken off. It is no surprise that Lee Sedol retired with the comments:
“With the debut of AI in Go games, I’ve realized that I’m not at the top even if I become the number one through frantic efforts. Even if I become the number one, there is an entity that cannot be defeated.” 6
RL has it’s own challenges. In order to deal with complex scenarios, an agent is receiving rewards and penalties for actions, trying to guide to learn the best strategy (or policy) to maximise a reward over time. Already hard when coding this for all kind of games, but especially challenging when applying it in the real world. Aside from all kind of paradoxes and dilemmas, such as the Trolley Problem.
Today, a special form of RL is heavily used to train AI algorithms: reinforcement learning from human feedback (RLHF). This used for example to evaluate whether a model followed instructions or generated safe outputs. A key issue is that superhuman AI might produce models too complex for human oversight.
With this little history as a foundation, let’s have a look at the next stage: research in machine supervised learning.
The Next Frontier
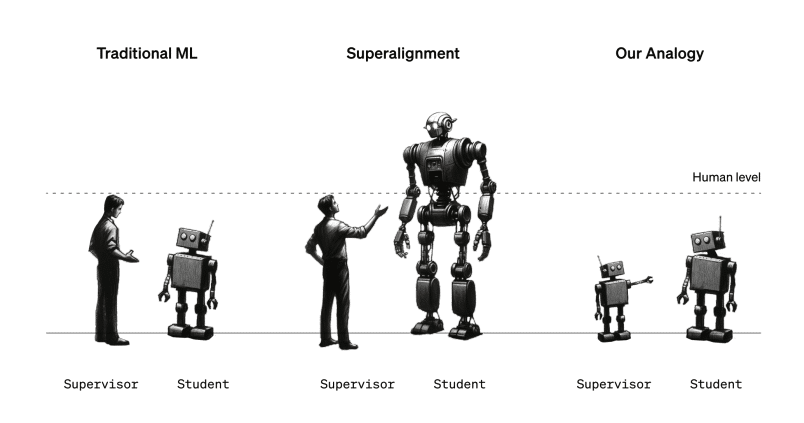
How do you keep advancing and training a new AI model on it’s pathway to becoming AGI, without losing the grip and understanding of how you got there? Enter supervised learning.
OpenAI has started to look into AI algorithms of weaker build to supervise the learning of newer models. Calling it Weak-to-strong learning, it basically is ChatGPT-2 training and reviewing ChatGPT-4.7 The key question: can we use a smaller (less capable) model to supervise a larger (more capable) model?
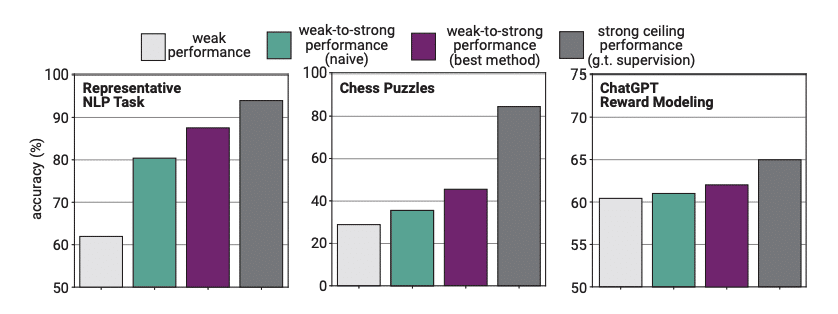
Image source (see footnote 7)
As you can see from the above, all new learning models are not capable of closing the gap (yet) between the strong ceiling and the weak-to-strong learning performance across multiple tasks, such as Chess puzzles.
Be on the lookout for more research and attention being paid to concepts like:
- Weakly-supervised learning
- Student-teacher training
- Robustness of pretraining and finetuning
- Debiasing
- Imitation and preference learning
- Scalable oversight
- Knowledge elicitation and honesty
It is early stages for this type of research and the progress of available data for learning as well as computing power will continue to drive AI innovation with ever increasing speed. The idea of leveraging more and more powerful models to keep training the next level of AI is a very interesting starting point I suggest to keep an eye on. You can find the latest research release here.
Takeaways
Wherever or however you are currently leveraging AI or ML – privately or for professional use, innovation will increase the power of these capabilities over the next years. Some of the key efforts you should focus on today are:
- Understanding and Managing Model Limitations
Be more aware of possible limitations and potential biases in the models you use. Cross check your own engagements with the likes of ChatGPT-4 and Bard with other sources and ensure to keep prompting these algorithms for a better understanding of how they provided you with an outcome. - Data Quality and Representation
How much quality is in the data you provide and does it have enough diversity in the data you leverage? - Transparency and Explainability
Can you explain (and understand) how AI in your use has made it’s decisions? - Follow the latest Research
Understand the leading research and what is being developed for the next stage of AI.
I hope this little article has given you a little insight into that next stage and an outlook into Superalignment and the related research.
Further reading
In case you liked this article and want to know more about the history of AI and the underlying alignment problem, I highly recommend the following book:

A jaw-dropping exploration of everything that goes wrong when we build AI systems and the movement to fix them.
“The Alignment Problem” by Brian Christian delves into the challenges and risks of AI systems, focusing on the urgent need to address ethical concerns and biases inherent in machine learning. It highlights issues like gender biases in resume selection, racial disparities in legal algorithms, and the increasing reliance on AI in critical areas like healthcare and transportation. Christian’s book, blending history and current trends, emphasizes the importance of solving these alignment issues to ensure AI technology aligns with human values and ethical standards.
A great book I can highly recommend with an attention to detail, especially when it comes to the history of AI and the steps taken up until today.
Footnotes:
- You can find my blog post about AlphaGo’s surprising move here. ↩︎
- MIT Technology Review: Rogue superintelligence and merging with machines: Inside the mind of OpenAI’s chief scientist ↩︎
- OpenAI: Weak-to-strong generalization ↩︎
- Sequence to Sequence Learning with Neural Network ↩︎
- Attention Is All You Need ↩︎
- Go master Lee says he quits unable to win over AI Go players ↩︎
- WEAK-TO-STRONG GENERALIZATION: ELICITING STRONG CAPABILITIES WITH WEAK SUPERVISION ↩︎