I love the application of games in the realm of artificial intelligence. From the early start of AI being tested on all kind of games to the need of training algorithms during Reinforcement Learning (RL) in complex environments. Games and AI have always been interwoven.
Are there any parallels we can draw from the world of games for the successful application of AI? I believe so. Take Tetris as an example.
On the 21st of December 2023, Willis Gibson (aka blue scuti) became the first human to break Tetris. A 34-year long journey and a welcome change of news, after AI mastering everything from Chess to Go: this time a human has beaten a game.
How did a 13-year old kid beat this classic game? It is a combination of human ingenuity, a community of enthusiasts analysing the game code base and the application of an AI algorithm.
Can something be learned from Tetris? I believe there is a huge value in gamifying tough challenges in a professional environment. Running tests. Bringing a little bit of that human ingenuity together with the now more and more publicly available AI algorithms. It is also a reminder though that AI alone cannot solve everything. It can augment what we do. What can we beat together next? I gathered 7 techniques I have learnt from how we have helped AI master these games and a little takeaway from how we have finally beaten Tetris.
The history – from Chess to Go
I wanted to take the opportunity to take a journey back in time to the beginning of computers playing games, all the way to modern AI algorithms training and learning on games. On this journey we will encounter texts by Edgar Ellen Poe on chess machines, crazy names of early GO programs and how a technique of Rolling changed the game of Tetris…
When Alan Turing asked the key question ‘Can machines think?’ in his famous 1950 paper1, he did so by creating the imitation game: “It is played with three people, a man (A), a woman (B), and an interrogator (C) who may be of either sex. The interrogator stays in a room apart from the other two. The object of the game for the interrogator is to determine which of the other two is the man and which is the woman. He knows them by labels X and Y, and at the end of the game he says either ‘X is A and Y is B’ or ‘X is B and Y is A’. The interrogator is allowed to put questions to A and B…” – now known as the Turing Test.
But even before Turing’s famous test, chess has already been a center of focus in the emerging computer research field.
Chess
“Programming a Computer for Playing Chess”2 by Claude Shannon in 1950 is the first published article on developing a chess-playing computer program. It provides 8 early predictions into the application of AI:
- (1) Machines for designing filters, equalizers, etc.
- (2) Machines for designing relay and switching circuits.
- (3) Machines which will handle routing of telephone calls based on the individual circumstances rather than by fixed patterns.
- (4) Machines for performing symbolic (non-numerical) mathematical operations.
- (5) Machines capable of translating from one language to another.
- (6) Machines for making strategic decisions in simplified military operations.
- (7) Machines capable of orchestrating a melody.
- (8) Machines capable of logical deduction.

I especially love the reference of Edgar Ellen Poe’s essay on “Maelzel’s Chess-Player”3, which is worth its own blog in the future and I highly recommend reading it. It comments on the work of Charles Babbage and then: The Turk, a chess playing automaton invented by Baron Wolfgang von Kempelen in 1769. This device has not just been encountered by Poe. It has defeated Benjamin Franklin in 1783 in Paris and Napoleon Bonaparte in 1809 in Vienna and I quote: “Perhaps no exhibition of the kind has ever elicited so general attention as the Chess-Player of Maelzel“.
The first example of a crude evaluation function for chess reads: f(P)=200(K-K’)+9(Q-Q’)+5(R-R’)+3(B-B’+N-N’)+(P-P’)-.5(D-D’+S-S’+I-I’) +.1(M-M’)+…4
The biggest issue of the early chess concept? Computing power: “Unfortunately a machine operating according to the type A strategy would be both slow and a weak player. It would be slow since even if each position were evaluated in one microsecond (very optimistic) there are about 10^9 evaluations to be made after three moves (for each side). Thus, more than 16 minutes would be required for a move, or 10 hours for its half of a 40-move game.“
Chess has always been an interesting research topic for another dimension as well: Bounded rationality. It is hard to make a rational decision when playing chess as 3 limits arise: (1) uncertainty about the consequences that would follow from each alternative (move), (2) incomplete information about the set of alternatives, and (3) complexity preventing the necessary computations from being carried out.5 Chess is a great example of how these three categories tend to merge in real world situations when making decisions.
From first human expert loss to AI chess mastery

David Levy

Garry Kasparov
Besides advancements around checkers and other games, it would take 29 years for a computer to achieve a first victory against a human in a competition at the highest tournament level. The get the computer to the tournament in Toronto took the researches a week(!) in 1978. David Levy (who wagered £1250 sterling to not be beaten) lost after 56 moves against Chess 4.7/CYBER 176 . Levy (picture to the left above) played the Greco Counter Gambit – which apparently lead to a game full of fireworks.
In order to even get to this stage, Levy and the authors of Chess 4.7 (Larry Atkin, Leith Gorlen and David Slate) had been working more or less together. Levy played a series of games between 1977 and 1978 to help train the trainers.
Fast forward to 1997. IBM’s Deep Blue beats World Chess Champion Garry Kasparov in a six-game tournament. Deep Blue had a very different evaluation function with over 8000 features. The speed of calculation also improved – a lot: “While performing all these activities, the speed of the system also varies. For example, tactical positions – when long and forcing moves are required, the deep blue algorithm can explore up to 100 million positions per second. On the other hand, for quieter positions, the search could go up to 200 million positions per second. It is said that in 1997 match with Garry Kasparov, the minimum search speed was 126 million positions per second, and the maximum number of the search speed was 330 million positions per second.“6
Kasparov might have been very competitive in 1997, but what is often overlooked is his participation in matches a year earlier. Murray Campbell – one of the original inventors of Deep Blue (pictured to the right above) – references the importance of these matches: “We learned a lot from the 1996 match […] We doubled the size of the system, made it twice as fast, but we added a lot more knowledge about chess – what makes a good position and bad position − into special-purpose hardware so it had better judgement about chess positions”7
And Kasparov referenced his learnings in a 2017 Ted Talk: “While licking my wounds, I got a lot of inspiration from my battles against Deep Blue. As the old Russian saying goes, if you can’t beat them, join them.”
An interesting side note: one of the key moves of Deep Blue might have been a bug: Kasparov believed he was facing a superior opponent as Deep Blue sacrificed a pawn: ” “It was a wonderful and extremely human move,” Kasparov noted, and this apparent humanness threw him for a loop. “I had played a lot of computers but had never experienced anything like this. I could feel — I could smell — a new kind of intelligence across the table.” “8. What he was initially unaware of was the IBM team working hard to fixing errors of the system in between games, leading to unintended moves.
Mastering Go

Lee Sedol
To compare complexities of games and understand why it took quite some time for Go to be mastered, it helps to compare the game state space. In Chess it is roughly 10^50. Go is a bit more complex with 10^170. If you are wondering: Tetris has it’s own complexities, but probably comes in at 10^60. There is also the question of an actual evaluation function for Go, as raised by Martin Müller in his paper Computer Go (2002)9.
You have to love early Go programs for their naming conventions. In the 1980s programs had names like: Dragon, Goliath, Go Intellect, Handtalk and Goemate.
Müller references some great milestones: “In 1991, Goliath won the yearly playoff between the Ing cup winner and three strong young human players for the first time, taking a handicap of 17 stones. Handtalk won both the 15 and 13 stone matches in 1995, and took the 11 stone match in 1997. Programs such as Handtalk, Go4++ and KCC Igo have also achieved some success in no-handicap games against human players close to dan level strength.“
The big impact for Go came with the application of Monte-Carlo tree search (MCTS). I will not go into all level of details on this, but It would highly recommend looking into it. Below is a comparison of the MCTS setup between the original AlphaGo and the later trained AlphaGo Zero.
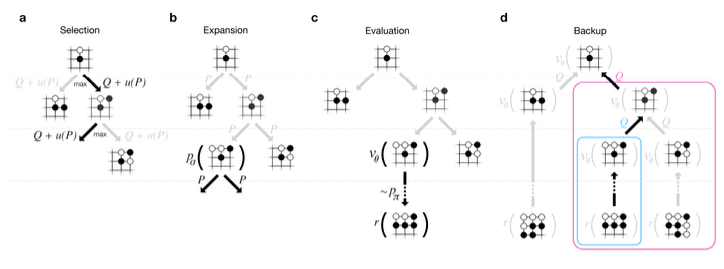
Monte-Carlo tree search in AlphaGo
a Each simulation traverses the tree by selecting the edge with maximum action-value Q, plus a bonus u(P ) that depends on a stored prior probability P for that edge. b The leaf node may be expanded; the new node is processed once by the policy network pσ and the output probabilities are stored as prior probabilities P for each action. c At the end of a simulation, the leaf node is evaluated in two ways: using the value network vθ; and by running a rollout to the end of the game with the fast rollout policy pπ, then computing the winner with function r. d Action-values Q are updated to track the mean value of all evaluations r(·) and vθ(·) in the subtree below that action.10
In 2016 AlphaGo then won against Lee Sedol. Advancements in AI have since created even more powerful versions of AlphaGo, beating the original version easily. All based on the advancements in reinforcement learning. To see the changes, allow me to show the new MCTS approach in the latest AlphaGo Zero version:
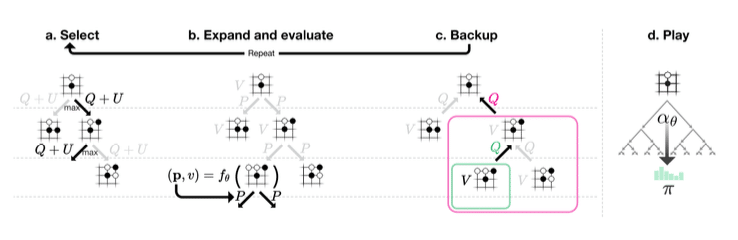
Monte-Carlo tree search in AlphaGo Zero
a Each simulation traverses the tree by selecting the edge with maximum action-value Q, plus an upper confidence bound U that depends on a stored prior probability P and visit count N for that edge (which is incremented once traversed). b The leaf node is expanded and the associated position s is evaluated by the neural network (P (s, ·), V (s)) = fθ (s); the vector of P values are stored in the outgoing edges from s. c Action-values Q are updated to track the mean of all evaluations V in the subtree below that action. d Once the search is complete, search probabilities π are returned, proportional to N 1/τ , where N is the visit count of each move from the root state and τ is a parameter controlling temperature. 11
How impactful reinforcement learning can be, shows the conclusion of the AlphaGo Zero paper. Allow me to quote:
“Our results comprehensively demonstrate that a pure reinforcement learning approach is fully feasible, even in the most challenging of domains: it is possible to train to superhuman level, without human examples or guidance, given no knowledge of the domain beyond basic rules. Further- more, a pure reinforcement learning approach requires just a few more hours to train, and achieves much better asymptotic performance, compared to training on human expert data. Using this approach, AlphaGo Zero defeated the strongest previous versions of AlphaGo, which were trained from human data using handcrafted features, by a large margin.
Humankind has accumulated Go knowledge from millions of games played over thousands of years, collectively distilled into patterns, proverbs and books. In the space of a few days, starting tabula rasa, AlphaGo Zero was able to rediscover much of this Go knowledge, as well as novel strategies that provide new insights into the oldest of games.“12
Tetris
After Chess and Go, can we learn something from Tetris? Created by Alexey Pajitnov in the USSR in 1984, the game of Tetris has been turned into a pop culture icon. I recommend watching the movie Tetris with Taron Egerton playing Henk Rogers (trailer). Like Chess and Go, Tetris has been a field for AI research for a long time.
AI Tetris Research
Pierre Dellarcherie developed the first evaluation function as: -4 x holes – cumulative wells – row transitions – column transitions – landing height + eroded cells…13
Research on applying various methods of machine learning in the game of Tetris goes all the way back to 1996. Early work by Tsitsiklis & Van Roy show various degrees of failure and success in applying several AI techniques. In their reports, Stevens & Pradhan and Lewis & Beswick all show the challenges of applying Reinforcement Learning to the game of Tetris. The main challenge being the the time lag between action and reward in the game. A possible interesting area to look into as OpenAI tried to tackle exactly this issue in their approach to Dota 214.
Given AI has been challenged with techniques like RL, allow me to introduce you to StackRabbit by Gregory Cannon. His AI project was able to take Tetris to level 237, before crashing. It takes a more simple approach, applying a mixture between game tree search and assessing 3 moves ahead in it’s decision making process. One of the key developments for the AI behind StackRabbit came from an expert player supporting the development: Fractal – one of the expert Tetris players, who later became the first human to crash the game at level 155 (which is the first possible crash achievable). Fractal’s personal “value function” when analysing the top of the game board helped Cannon in developing an improved algorithm to play the game.
Beating the unbeaten game
But how did Willis Gibson (aka blue scuti) beat the game? I would not be able to describe this in as fantastic detail as aGameScout did in his Youtube video below. Have a look.
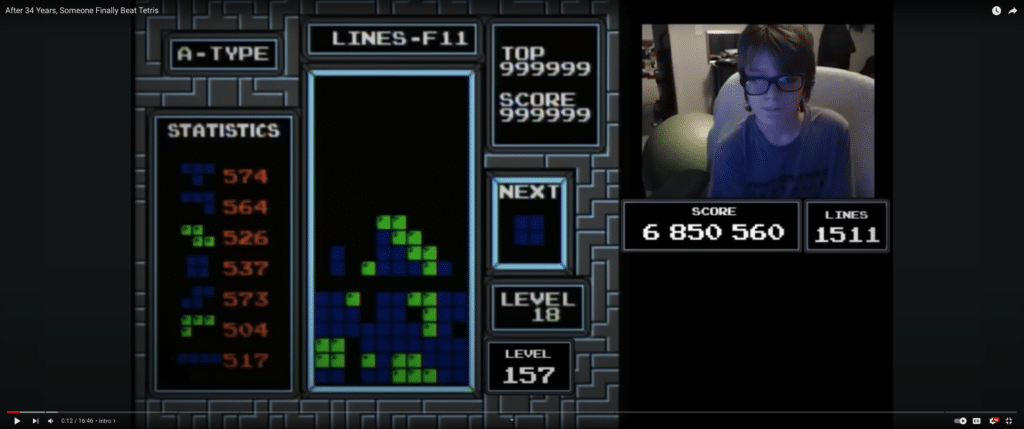
After 34 Years, Someone Finally Beat Tetris – by aGameScout on Youtube
Considering the advent of new techniques, such as Hypertapping and especially Rolling by Cheez aka Christopher “CheeZ” Martinez has shown the power of human inventions on the pathway to finally beating the game. Developing an entire new way of playing the game of Tetris can easily be compared with AI researches trying new techniques of RL to adapt to the challenges of Tetris (or other games).
Another accomplishment: after 38mins of gameplay at a high speed, it is also a showcase of endurance and determination. The work required to even get to level 157 and especially keeping calm after shooting beyond 155 are unbelievable.
A success also worth of some nice surprises. After making headlines, I especially loved the surprise of NBC News gave Willis: they invited Alexey Pajitnov into the call with him.
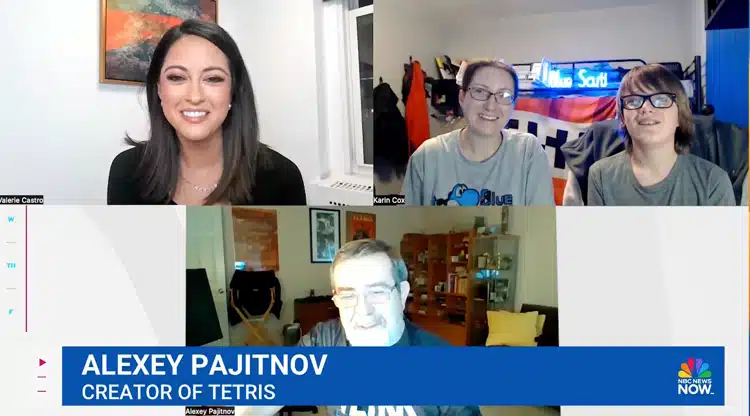
When asked, what he would tell young players of Tetris watching his success, Blue Scuti invokes none other than Benjamin Franklin with his response: “If you set your mind to something and you put work into it, most likely you will get it.“
Learnings to apply
Given the impact of AI on solving games, I believe it is important to also take our own learnings from HOW these algorithms have started to succeed and beat games and merge it with the great story from kids beating Tetris.
Here are 7 techniques I want to suggest for applying in your own professional career:
- Learning from Experience: In RL, AI modules improve over time as they accumulate more experiences. I love to draw a parallel here to hiring a mentor or coach to learn from the extensive experience of an expert.
- Trial and Error Learning: Just as an AI system learns through trial and error in games like Chess, Go or Tetris, I believe it is important to encourage experimentation, where failure is seen as an opportunity to learn and adapt strategies. This mirrors the RL principle where an agent improves its performance based on the outcomes of its actions.
- Adaptive Decision Making: Feedback plays an important role in AI decision making through RL. I believe that the value of feedback is clearly shown, but how often do we actively seek it out to apply it to our decision making process?
- Risk Management: Just as RL involves calculating risks and potential rewards to make optimal decisions, better understanding real risk and rewards in a professional context can be a key to success (or the avoidance of failure). I find the professional environment often too risk averse, stifling the chance of potential innovation and possible rewards.
- Goal-Oriented Strategies: RL algorithms are designed to maximize a reward. Similar to these goal-setting techniques I highly recommend the application of OKRs in a professional environment. I recommend reading: Measure What Matters.
- Customization and Personalization: In RL, algorithms are often tailored to specific tasks or environments. Similarly, I believe it is of the upmost importance to adapt strategies and solutions to meet the unique needs of a project, team, or customer. A more personalised and bespoke approach ensures that the solutions are effective and relevant.
- Look at it with the eyes of a kid: have fun and change the game. What better way to learn from Cheez, Blue Scuti and Fractal?
- Turing, A. M. (1950). Computing machinery and intelligence. Mind, 59(236), 433-460. ↩︎
- Claude Shannon: “Programming a Computer for Playing Chess” ↩︎
- Edgar Allan Poe: “Maelzel’s Chess-Player” ↩︎
- Claude Shannon: “Programming a Computer for Playing Chess” ↩︎
- Simon, Herbert A. Theories of bounded rationality. Decision and organization, 1(1):161–176, 1972. ↩︎
- https://www.professional-ai.com/deep-blue-algorithm.html ↩︎
- https://aibusiness.com/ml/25-years-ago-today-how-deep-blue-vs-kasparov-changed-ai-forever ↩︎
- Did Deep Blue Beat Kasparov Because of a System Glitch? ↩︎
- Müller: Computer Go ↩︎
- https://www.nature.com/articles/nature16961 ↩︎
- https://www.nature.com/articles/nature24270 ↩︎
- Mastering the game of Go without Human Knowledge ↩︎
- The Game of Tetris in Machine Learning ↩︎
- OpenAI: Dota 2 with Large Scale Deep Reinforcement Learning ↩︎